for Resilient Multi-Agent LLM Reasoning
by: Rui Jerry H, Anastasia M, Wendy L, Lei D
AI for Math poster, accepted at NuerIPS and AAAI (video link)
Motivations
Inference-Time Computation Challenges
- Large Language Models (LLMs) show strong reasoning capabilities but are limited by their pre-trained knowledge scope.
- Existing strategies for enhancing reasoning have significant limitations at inference time:
○ Self-Correction often reinforces the model’s initial biases.
○ Multi-Agent Collaboration frequently suffers from a lack of efficient
coordination, which can lead to collective errors and reasoning collapse from low-quality peer feedback. - High-performing verifiers can detect errors but require substantial training to be reliable.
- Optimizing multi-agent architecture and reasoning processes often require or assume symmetric role for each agent limiting practicality for deployment at inference time.
Key Insights
The Adaptive Coopetition (AdCo) framework addresses these limitations by
leveraging these core insights:
- Adaptive Strategy is Key: A dynamic, signal-guided ‘coopetition’ strategy is more effective than rigid collaboration or competition. Agents must adaptively choose whether to collaborate (absorb high-scoring peer reasoning) or compete (invite peer criticism) to iteratively refine their reasoning.
- Coarse Signals are Sufficient: You don’t need a high-precision verifier. Coarse verifier signals (outputs of moderate precision) can effectively guide the adaptive strategy, filtering out bad feedback and amplifying
good feedback without extensive training. - Low Quality Feedback Isolation Reduces Reasoning Collapse: In collaboration, agents choose the highest-scoring feedback to merge with to avoid regressing in solution quality. In competition, agents
request feedback only from highest-scoring peer agents.
Results: Accuracy and Stability
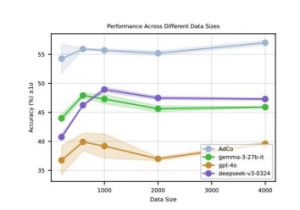
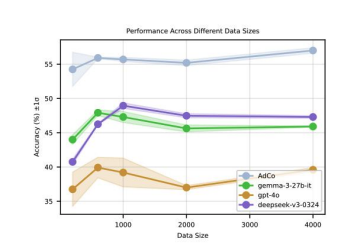
- Accuracy: AdCo demonstrates a clear and significant improvement in accuracy over all baselines on DeepMath-103K.
- Stability: AdCo maintains consistently robust performance across different data sizes (600–4000 samples), with a low standard deviation (<1%).
Ablation Study: Revised UCB & Impact of Agent Capability
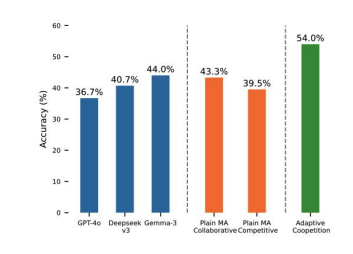
- The Revised UCB action policy outperforms a simple flipping rule (collaborate if PR > 0.5, compete otherwise), yielding a higher accuracy (55.70% vs. 54.08% at 1,000 samples).
- AdCo boosts accuracy even for strong models (74.75% → 80.5%) and works best when agents have similar strength but diverse reasoning. Majority voting can dilute individual impact.